
回归问题中的小套路
回归问题中的小套路
Kaggle Houseprice
Kaggle中的入门竞赛Houseprice竞赛是一个经典的回归问题,下面将以其中的特征工程代码演示一下回归问题中的常见套路。
1. 缺失值处理
缺失值处理通常有如下几种方式:
- 以特定值填充,有些NAN值具有特殊意义
- 使用该特征的均值或中位数进行填充,适用于数值型特征
- 使用该特征的众数进行填充,适用于分类型或离散型特征
- 参考同类特征进行填充,如Houseprice中可以参考同处一个Neighborhood的特征的数值分布进行缺失值填充
- 直接删除,适用于缺失值过多,且该特征方差过小的情况
1 | # 区域因素 |
2. 添加新特征
利用现有的特征,添加新特征,这是机器学习项目中最具创造性的步骤,特征工程决定了最终得分的上限,能否找到项目中的Golden Feature是项目成败的关键。
这个步骤主要依靠对于特定业务的了解。
套路的话主要是对特征的组合或者添加多次项转化成多项式回归。
我曾见过一个很生猛的套路:对任意两列特征做加减乘运算,生成新的特征,然后再进行筛选,如果你的电脑性能够强,对项目业务又不太熟悉,不妨尝试一下这种方法,参考代码
这个项目中我只添加了三个特征,效果尚可(我曾按国内房产评估方法为每个test样本添加了可比实例价格,效果不好)。
1 | data['Remodeled'] = (data['YearBuilt'] != data['YearRemodAdd']) * 1 |
3. 特征处理
连续数值型特征
对数值型特征的处理方式很简单,主要是对偏态分布的数据进行标准化处理,对于偏度大于某个阈值的特征转为正态分布或者取对数处理(如果觉得设定偏度阈值太麻烦了,可以直接对所有数值型特征进行处理)。
1 | numeric_feats = data.drop(['AVG_PRICE','SalePrice'],axis=1).dtypes[(data.dtypes != 'object') & (data.dtypes != 'datetime64[ns]')].index # 获取数值列 |
在分类和关联分析问题中,还会有连续变量离散化的操作。
分类型或离散型特征
字符型的分类特征无法直接带入回归模型中运算,需要进行数值化,然而进行数值化之后,模型会考虑各数值之间的距离:比如把红黄绿三种颜色编号为123,那么模型会认为红色和黄色之间的距离比红色和绿色之间的距离近,从而导致模型偏差。
通常会采用的方式是对特征进行独热编码,可以通过sklearn中的OneHotEncoder()和pandas中的get_dummies()实现。
4. 特征筛选
特征筛选的筛选主要有两类方式,一种我称之为统计筛选,另一种是模型筛选
统计筛选
- 方差选择法
- 相关系数法
- 卡方检验法
- 互信息法
这些方法中,方差选择法是单独计算每个特征的方差,选择方差高于阈值的特征。其他三种方法是采用不同的手段计算特征与因变量(预测目标)之间的相关性来筛选特征。
模型筛选
模型筛选常见的也有两种方式:
- 使用模型中的特征重要性进行排序
- 逐步添加或减少特征,如果模型得到改善则保留更改
其实两种方式差不多,只是方法1中的特征重要性只考虑单特征对模型的影响,而方法2中考虑的是不同特征组合的模型效果,在方法2中,本地cv验证方法的选取非常重要。我采用的是第二种方法,代码如下:
1 | def backward_cv(train_data,clf = RidgeCV(alphas=[1e-6,1e-5,1e-4,1e-3,1e-2,1e-1,1])): |
降维
- PCA
- LDA
降维通常是用来减少特征中的线性相关量,控制模型中的维度,通常使用与模型中特征量过大,又不好删除的情况(不确定哪些因素对模型没有用)。这个方法我暂时没有用到。
5. 模型调参
很多模型中都有超参数,就是那种不确定会对模型影响不明确的因素。sklearn提供了两种调参方式,分别是网格搜索GridSearchCV()和随机搜索RandomizedSearchCV()。GridSearchCV效果更稳定,RandomizedSearchCV就有点看人品了,效果好的时候比GridSearchCV好,差的时候会很差。
下面是我用的调参参数
1 | rid = search_model(Ridge(),x,y,params = { |
6. 模型融合
模型融合的目的是提高模型的泛化能力,通常会采用得分相近、但是原理相差较大的几个模型进行融合,比如回归模型中可以用Rdige/Lasso回归 + 随机森林 + xgboost 这样的组合方式。
组合方式也有多种:
Average
最简单的融合方式,就是把多个线性模型的结果进行线性组合。如果在分类问题中可以使用类似的Voting方法,这种简单又有效的方法当然要尝试一下:
1 |
|
Bagging
多次从总样本中有放回地抽取样本,通过得到的子样本建立多个子模型,然后使用Average将这些子模型进行融合。随机森林算法就是衍生于bagging算法
Boosting
多次迭代训练,每次训练完之后,将预测效果较差的样本的权重加大,然后再对训练出来的子模型结果进行加权的线性组合(与Average类似),sklearn中提供了Adaboost和GBDT函数,可以直接调用。
Stacking
Stacking是比较难描述的算法,原理如下图所示: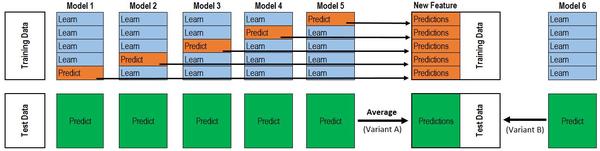
在Python中没有现成的模块可用,需要自己写:
1 | class stack_model: |
整个思路就是这样,现在模型还在调整中,如果效果比较好的话,我会把源代码分享出来。